Es un modelo para construir sistemas de información, que se sustenta en la idea de repartir el tratamiento de la información y los datos por todo el sistema informático, permitiendo mejorar el rendimiento del sistema global de información Es la tecnología que proporciona al usuario final el acceso transparente a las aplicaciones, datos, servicios de cómputo o cualquier otro recurso del grupo de trabajo y/o, a través de la organización, en múltiples plataformas. El modelo soporta un medio ambiente distribuido en el cual los requerimientos de servicio hechos por estaciones de trabajo inteligentes o "clientes'', resultan en un trabajo realizado por otros computadores llamados servidores
¿QUE ES UN CLIENTE?
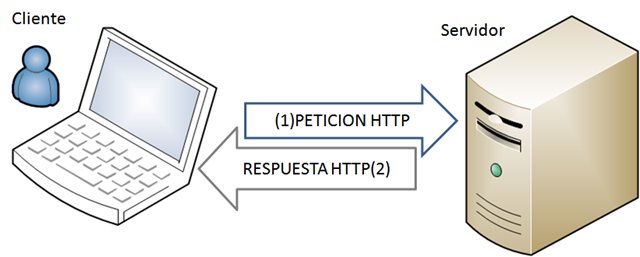
Es el que inicia un requerimiento de servicio. El requerimiento inicial puede convertirse en múltiples requerimientos de trabajo a través de redes LAN o WAN. La ubicación de los datos o de las aplicaciones es totalmente transparente para el cliente.
¿QUE ES UN SERVIDOR?
Es cualquier recurso de cómputo dedicado a responder a los requerimientos del cliente. Los servidores pueden estar conectados a los clientes a través de redes LANs o WANs, para proveer de múltiples servicios a los clientes y ciudadanos tales como impresión, acceso a bases de datos, fax, procesamiento de imágenes, etc. Evolución del modelo Cliente Servidor
· Mono-capa
· Data Base Server – Computación centralizada
· Two-Tier – Proceso de transacciones · Multi-tier Client/Server
· Three-tier · Multi-tier
· N-tier
Aplicaciones mono-capa
Entendemos por aplicaciones mono-capa, aquellas que tanto la propia aplicación como los datos que maneja se encuentran en la misma máquina y son administradas por la misma herramienta: podríamos decir que son una sola entidad
Modelo En Dos Capas (Two-Tier Model)
En una arquitectura cliente/servidor clásica tenemos dos "capas" (two-tier): Una donde está el cliente que implementa la interface. Otra donde se encuentra el gestor de bases de datos que trata las peticiones recibidas desde el cliente. La lógica de la aplicación se encuentra por tanto repartida entre el cliente y servidor. Un ejemplo de esta configuración podría ser un applet Java que se carga en el navegador del cliente y trabaja directamente con la base de datos mediante JDBC.
Ventajas de este modelo:
Se mantiene una conexión persistente con la base de datos. Se minimizan las peticiones en el servidor trasladándose la mayor parte del trabajo al cliente. Se gana en rendimiento gracias a la conexión directa y permanente con la base de datos. A través de una única conexión se realiza el envío y recepción de varios datos.
Inconvenientes:
La más importante desventaja, es que esta solución es muy dependiente del tipo controlador JDBC que se utilice para acceder a la base de datos. El acceso se realiza desde el cliente y esto significa que es él el que tiene que tener instalado en su sistema los controladores necesarios para que se produzca la comunicación con la base de datos. Además hay que tener en cuenta que el modelo de seguridad de Java impide que desde un applet sin validar (lo que se conoce como untrusted applet), como lo son la mayoría de los que se ejecutan en un navegador
Modelo en Tres Capas (Three-Tier Model)
Con la arquitectura cliente/servidor en tres capas (three-tier) añadimos una nueva capa entre el cliente y el servidor donde se implementa la lógica de la aplicación. De esta forma el cliente es básicamente una interface, que no tiene por qué cambiar si cambian las especificaciones de la base de datos o de la aplicación; queda aislado completamente del acceso a los datos. En este caso se tiene total libertad para escoger dónde se coloca la lógica de la aplicación: en el cliente, en el servidor de base de datos, o en otro(s) servidor(es). También se tiene total libertad para la elección del lenguaje a utilizar. Se utiliza un lenguaje de tipo general (probablemente C) por lo que no existen restricciones de funcionalidad.
Ventajas de este modelo:
No existe ningún problema con respecto al tipo de controlador JDBC utilizado para acceder a la base de datos.Todos los recursos necesarios para establecer la conexión con la base de datos se encuentran en el servidor y por tanto, el cliente no necesita instalar nada adicional en su máquina para poder acceder a la base de datos. Esta arquitectura proporciona considerables mejoras desde el punto de vista de la portabilidad de la aplicación, escalabilidad, robustez y reutilización del código. Asimismo facilita las tareas de migración o cambios en el sistema gestor de la base de datos. Desaparecen las restricciones debidas a las limitaciones de los applets impuestas por el modelo de seguridad de Java. Inconvenientes: Esta solución es algo menos eficiente que la del modelo de dos capas, ya que hemos añadido una capa intermedia más de software.




REFERENCIAS
http://docente.ucol.mx/sadanary/public_html/bd/cs.htm